Cascaded Deep Video Deblurring Using Temporal Sharpness Prior
Jinshan Pan, Haoran Bai, and Jinhui Tang

Abstract
We present a simple and effective deep convolutional neural network (CNN) model for video deblurring. The proposed algorithm mainly consists of optical flow estimation from intermediate latent frames and latent frame restoration steps. It first develops a deep CNN model to estimate optical flow from intermediate latent frames and then restores the latent frames based on the estimated optical flow. To better explore the temporal information from videos, we develop a temporal sharpness prior to constrain the deep CNN model to help the latent frame restoration. We develop an effective cascaded training approach and jointly train the proposed CNN model in an end-to-end manner. We show that exploring the domain knowledge of video deblurring is able to make the deep CNN model more compact and efficient. Extensive experimental results show that the proposed algorithm performs favorably against state-of-the-art methods on the benchmark datasets as well as real-world videos.
Downloads
Citation
@InProceedings{Pan_2020_CVPR,
author = {Pan, Jinshan and Bai, Haoran and Tang, Jinhui},
title = {Cascaded Deep Video Deblurring Using Temporal Sharpness Prior},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}
Proposed Algorithm
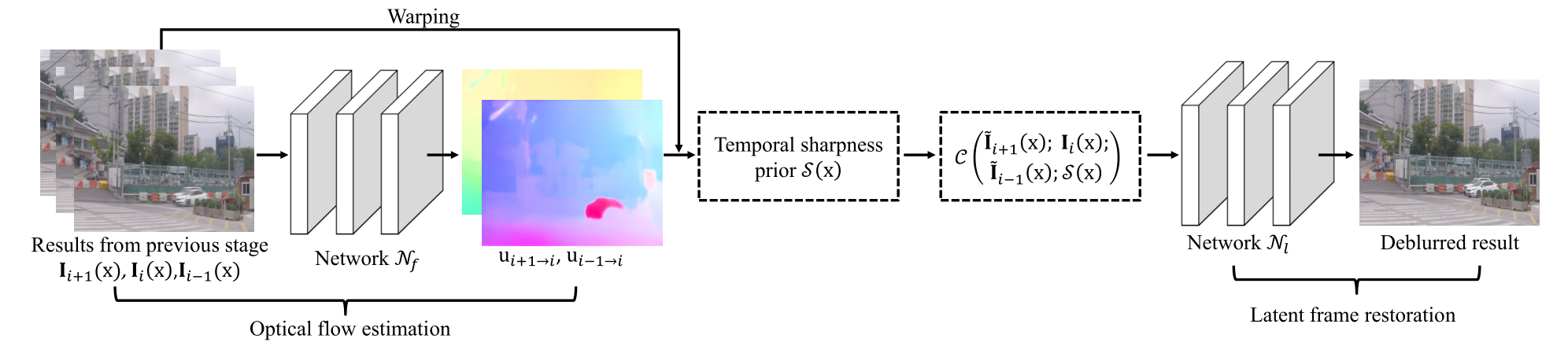
The proposed algorithm contains the optical flow estimation module, latent image restoration module, and the temporal sharpness prior. For the optical flow estimation, we use the PWC-Net [5] to estimate optical flow. For the latent image restoration module, we use an encoder-decoder architecture based on [26]. However, we do not use the ConvLSTM module. Other network architectures are the same as [26].
To effectively train the proposed algorithm, we develop a cascaded training approach and jointly train the proposed model in an end-to-end manner. At each stage, it takes three adjacent frames estimated from the previous stage as the input and generates the deblurred results of the central frame. When handling every three adjacent frames, the proposed network shares the same network parameters. The variables \( \tilde{I}_{i+1}(x) \) and \( \tilde{I}_{i-1}(x) \) denote the warped results of \( I_{i+1}(x+u_{i+1\rightarrow i}) \) and \( I_{i-1}(x+u_{i-1\rightarrow i}) \), respectively.
Temporal sharpness prior
As demonstrated in [4], the blur in the video is irregular, and thus there exist some pixels that are not blurred. Following the conventional method [4], we explore these sharpness pixels to help video deblurring. The sharpness prior is defined as: \[ S_i(x) = exp(-\frac{1}{2} \sum_{j\&j\neq0}D(I_{i+j}(x+u_{i+j \rightarrow i}); I_i(x))) \tag{10} \] where \( D(I_{i+j}(x+u_{i+j \rightarrow i}); I_i(x)) \) is defined as \( \left \| I_{i+j}(x+u_{i+j \rightarrow i} - I_i(x) \right \|^2 \).
Based on (10), if the value of \( S_i(x) \) is close to 1, the pixel \(x\) is likely to be clear. Thus, we can use \( S_i(x) \) to help the deep neural network to distinguish whether the pixel is clear or not so that it can help the latent frame restoration. To increase the robustness of \( S_i(x) \), we define \( D(.) \) as: \[ D(I_{i+j}(x+u_{i+j \rightarrow i}); I_i(x)) = \sum_{y\in \omega(x)} \left \| I_{i+j}(x+u_{i+j \rightarrow i} - I_i(x) \right \|^2 \tag{11} \] where \( \omega(x) \) denotes an image patch centerd at pixel \( x \).
Quantitative Results
We further train the proposed method to convergence, and get higher PSNR/SSIM than the result reported in the paper.
Quantitative results on the benchmark dataset by Su et al. [24]. All the restored frames instead of randomly selected 30 frames from each test set [24] are used for evaluations. Note that: Ours* is the result that we further trained to convergence, and Ours is the result reported in the paper.
![Table 1. Quantitative evaluations on the video deblurring dataset [24] in terms of PSNR and SSIM.](https://s1.ax1x.com/2020/03/31/GQOAv6.png)
Quantitative results on the GOPRO dataset by Nah et al.[20].
![Table 2. Quantitative evaluations on the video deblurring dataset [20] in terms of PSNR and SSIM.](https://s1.ax1x.com/2020/03/31/GQYZi8.png)
Visual Comparisons
Here are some visual comparisons with state-of-the-art methods. The proposed algorithm generates much clearer frames. More visual results are included in supplementary materials.
![Figure 2. Deblurred results on the test dataset [24].](https://s1.ax1x.com/2020/03/31/GQt01g.png)
![Figure 3. Deblurred results on the test dataset [20].](https://s1.ax1x.com/2020/03/31/GQtgA0.png)
![Figure 4. Deblurred results on a real video from [4].](https://s1.ax1x.com/2020/03/31/GQtf9U.png)
![Supp-Figure 8. Deblurred results on the test dataset [3].](https://s1.ax1x.com/2020/04/02/GJQ7aq.png)
![Supp-Figure 7. Deblurred results on the test dataset [4].](https://s1.ax1x.com/2020/03/31/GQrpkj.png)
![Supp-Figure 6. Deblurred results on the test dataset [4].](https://s1.ax1x.com/2020/03/31/GQD6YR.png)
Contact
If you have any question, please contact us by:
- E-mail: baihaoran@njust.edu.cn
- Github Issue: https://github.com/csbhr/CDVD-TSP/issues